Omnipresent Yet Overlooked: Heat Kernels in Combinatorial Bayesian Optimization
What if the most successful algorithms for optimizing drug molecules and neural architectures have been using the same mathematical trick all along—without anyone realizing it?
⚡ TL;DR
Problem: Dozens of "different" kernels exist for optimizing over discrete choices (like chemical compounds or network architectures), but no one knows how they actually relate to each other.
Old answer: Researchers kept inventing new kernels with different names (COMBO, CASMOPOLITAN, Bounce, etc.) and benchmarking them, assuming they're fundamentally different approaches.
New answer: This paper proves that nearly all successful combinatorial kernels are either heat kernels in disguise or closely related variants—they've been the same approach all along, just wearing different mathematical costumes.
Key Insight: Modeling heat diffusion on a graph where "nearby" means "one substitution away" naturally captures similarity between discrete choices—and it turns out that's exactly what the best algorithms have been doing without knowing it.
1 The Story in Plain English
Imagine you're trying to design the perfect molecule for a new drug. You can't test every possible molecule (there are trillions), so you need to be smart about which ones to try. The key question is: if molecule A works well, which other molecules should I test next?
To answer this, you need a similarity measure: a way to say "molecules that differ by only one atom are pretty similar, molecules that differ by two atoms are less similar," and so on. This similarity measure is called a kernel, and it's the heart of Bayesian Optimization—the fancy term for "smart trial-and-error search."
Over the past decade, researchers created a zoo of different kernels with different names: COMBO, CASMOPOLITAN, Bounce, BODi, and more. Each paper claimed their kernel was novel and ran benchmarks showing it outperformed others. But here's the twist: no one actually understood how these kernels relate to each other. Were they truly different approaches, or just variations on a theme?
This paper answers that question with a stunning revelation: nearly all of these "different" kernels are secretly the same thing. Specifically, they're all heat kernels—a concept from physics that models how heat diffuses through a network.
💡 The Coffee Cup Analogy
Think of a network of coffee shops in a city. You put a hot cup of coffee in one shop, and over time, the warmth spreads to neighboring shops, then their neighbors, and so on. Shops that are one block away get warm quickly; shops that are ten blocks away take much longer.
Heat kernels work the same way for discrete choices. If you test a molecule with atoms [Carbon, Nitrogen, Oxygen] and it works well, the kernel says: "Molecules that are one substitution away (like [Carbon, Nitrogen, Hydrogen]) are probably good too." This "warmth" of good performance diffuses through the space of possibilities, guiding your search.
The paper's key contributions are threefold:
- Unification: They prove that COMBO and CASMOPOLITAN (two heavily-cited methods) use mathematically identical kernels, despite appearing completely different.
- Speed: This insight allows a 2× faster implementation of COMBO's kernel.
- Robustness: Heat kernels don't have hidden biases (unlike some alternatives), making them more reliable in practice.
Before We Dive In: What You'll Need
- Bayesian Optimization: A method for finding the maximum of expensive black-box functions by building a probabilistic model and using it to decide where to sample next.
- Gaussian Process (GP): A probabilistic model that represents uncertainty about a function. Think of it as drawing smooth curves through known points, with wider error bars far from data.
- Kernel (Covariance Function): A function that measures similarity between two inputs. High kernel value means "these inputs should have similar outputs."
- Hamming Distance: The number of positions where two sequences differ. [A,B,C] and [A,X,C] have Hamming distance 1.
- Graph Laplacian: A matrix that encodes a graph's structure, used for studying diffusion and connectivity. It's like the discrete version of the Laplacian operator in calculus.
- Heat Equation: Describes how heat (or any diffusive quantity) spreads over time. Solutions to the heat equation tell us temperature at each location and time.
- Combinatorial Space: A space where inputs are discrete choices (like selecting from menus), not continuous numbers. Example: picking 5 toppings from a list of 20.
- ARD (Automatic Relevance Determination): Giving each input dimension its own lengthscale parameter, so the model can learn which features matter more.
Context: If you've used scikit-learn's GaussianProcessRegressor, you've used kernels! This paper shows that for discrete choices (molecule structures, network architectures), the RBF kernel—after a simple one-hot encoding—is actually a heat kernel on a graph. That elegant connection was hiding in plain sight.
2 The Problem: A Zoo Without a Map
💭 Wait, What's Optimization on Discrete Spaces?
In continuous optimization, you search over numbers: find the best learning rate in [0.001, 0.1]. In combinatorial optimization, you search over discrete choices: find the best molecule from a dropdown menu of atoms at each position.
The RBF kernel works great for continuous spaces because distance is obvious: 0.01 is close to 0.02. But for discrete choices, what does "close" even mean? Is [Red, Circle] close to [Blue, Circle] or [Red, Square]? We need a different notion of similarity.
Let's make this concrete. Suppose you're optimizing a molecule with three positions, where each position can be one of four atoms: {C, N, O, H}. Your input space looks like:
Total possibilities: 4 × 4 × 4 = 64 molecules
Now, suppose you test (C, N, O) and it scores 0.9 (good!). What should you test next? You need a kernel $k(\mathbf{x}, \mathbf{x}')$ that tells you which untested molecules $\mathbf{x}'$ are "similar" to your good result $\mathbf{x} = $ (C, N, O).
Here's the challenge: researchers invented many different kernels for this task, but no one understood their relationships:
COMBO (2019)
Build a graph where nodes are molecules and edges connect molecules 1 substitution apart. Apply a "diffusion kernel" using the graph Laplacian's eigenvalues.
CASMOPOLITAN (2021)
Use the RBF kernel, but replace Euclidean distance with Hamming distance (number of differing positions).
Bounce (2023)
Use the Matérn kernel (a generalization of RBF) with Hamming distance.
BODi (2023)
Embed categorical variables into an ordinal space using "dictionaries," then use standard continuous kernels.
On the surface, these look like completely different approaches: COMBO uses graph theory, CASMOPOLITAN uses Hamming distances, BODi uses embeddings. Papers benchmarked them against each other, showing different winners on different problems.
🤨 Reality Check
Q: If these kernels are so different, why do they all seem to work reasonably well?
A: Maybe they're not actually that different. Maybe there's a hidden connection that explains why they all work—and that's exactly what this paper discovers.
🔥 Interactive: Heat Diffusion on Hamming Graph
This Hamming graph shows 8 binary strings (000 to 111). Each node connects to neighbors that differ by 1 bit. Click any node to place "heat" and watch it diffuse across the graph—this is exactly how heat kernels measure similarity!
💡 Key Insight: Heat spreads to 1-hop neighbors first, then 2-hop, then 3-hop. This graph distance equals Hamming distance, which is why Hamming kernels = Heat kernels!
3 The Key Insight: They're All Heat Kernels
🔢 Concrete Example: Two Approaches, Same Answer
Let's compute the kernel value $k(\mathbf{x}, \mathbf{x}')$ for two molecules that differ in exactly 1 position. Say $\mathbf{x} = $ (C,N,O) and $\mathbf{x}' = $ (C,N,H).
CASMOPOLITAN approach (Hamming-based):
Hamming distance $h(\mathbf{x}, \mathbf{x}') = 1$
Kernel: $k(\mathbf{x}, \mathbf{x}') = \exp(-h / \ell^2) \approx 0.606$ (for $\ell=1$)
COMBO approach (Graph Laplacian):
Build Hamming graph, compute Laplacian eigenvalues, apply diffusion formula...
Result: $k(\mathbf{x}, \mathbf{x}') \approx 0.606$ (exact same!)
This isn't a coincidence. The paper proves these two methods are computing the exact same function, just via different mathematical routes.
The paper's central theorem is elegant: CASMOPOLITAN and COMBO are mathematically equivalent. Both are computing a heat kernel on a Hamming graph—COMBO does it explicitly using graph theory, while CASMOPOLITAN does it implicitly using Hamming distances.
💎 The "Aha!" Moment
A heat kernel measures similarity by simulating heat diffusion: drop heat at molecule $\mathbf{x}$, wait a tiny bit, and see how warm molecule $\mathbf{x}'$ gets. If they're neighbors on the graph, $\mathbf{x}'$ warms up quickly (high kernel value). If they're far apart, barely any heat reaches $\mathbf{x}'$ (low kernel value).
The parameter $\beta$ controls diffusion time: small $\beta$ means heat spreads fast (distant molecules get similar values), large $\beta$ means heat spreads slowly (only immediate neighbors matter).
Why does this work? Because the Hamming distance naturally encodes graph distance: molecules that differ by 1 substitution are 1 hop away, molecules that differ by 2 substitutions are 2 hops away, etc. So Hamming-based kernels and graph-based heat kernels must be computing the same thing.
The Unification: A Bigger Picture
The paper doesn't stop at COMBO and CASMOPOLITAN. It introduces two general classes of kernels and proves they're equivalent:
🔵 Hamming Kernels
Definition: Any kernel that only depends on the Hamming distance $h(\mathbf{x}, \mathbf{x}')$.
$k(\mathbf{x}, \mathbf{x}') = \kappa(\sqrt{h(\mathbf{x}, \mathbf{x}')})$
Examples: CASMOPOLITAN (RBF), Bounce (Matérn), Rational Quadratic (new!)
🟢 Φ-Kernels (Graph-based)
Definition: Kernels defined via a regularization function $\Phi(\lambda)$ of the graph Laplacian's eigenvalues.
$k(x, x') = \sum_j \Phi(\lambda_j) f_j(x) f_j(x')$
Examples: COMBO (diffusion), Graph Matérn (new!)
Theorem: For Hamming graphs where all categories have the same number of choices, the class of Hamming kernels and the class of Φ-kernels are identical. Every Hamming kernel is a Φ-kernel, and vice versa.
🤔 Wait, You Just Made It More Complex!
It looks like we replaced "several named kernels" with "two abstract classes." How is that simpler?
Answer: The abstraction reveals the structure. Now we know: (1) you can invent new kernels by picking any isotropic kernel and replacing distance with Hamming distance, or (2) by picking any regularization function $\Phi$. Both routes give valid kernels, and when categories have equal sizes, both routes explore the same space. This is like discovering that "addition" and "counting up" are the same operation—suddenly, a dozen scattered tricks become instances of one principle.
📐 Math Deep Dive: The Heat Kernel Formula
Here is the formal definition of a heat kernel on a graph $\mathcal{G}$:
Where:
- $(\lambda_j, f_j)$ are the eigenpairs of the graph Laplacian $\boldsymbol{\Delta} = \mathbf{D} - \mathbf{A}$
- $\mathbf{A}$ is the adjacency matrix, $\mathbf{D}$ is the degree matrix
- $\beta > 0$ is a hyperparameter controlling diffusion time (smaller $\beta$ = faster diffusion)
- $x, x'$ are nodes in the graph (i.e., molecules in our space)
For a Hamming graph (where edges connect molecules differing by 1 substitution), this simplifies to:
Where $g_i = |\mathcal{X}_i|$ is the number of choices for dimension $i$, and $\delta(\cdot, \cdot)$ is the Kronecker delta (1 if equal, 0 otherwise).
The magic: This formula looks complicated, but when you expand it out, it's exactly equivalent to CASMOPOLITAN's simple RBF-with-Hamming formula. The paper proves this in Theorem 1.
🔬 Proof Sketch: Why CASMOPOLITAN = COMBO
The proof has three steps:
Step 1: One-hot encoding connects Hamming and Euclidean distances
The Hamming distance $h(\mathbf{x}, \mathbf{x}')$ equals $\frac{1}{2}\|\mathbf{z} - \mathbf{z}'\|_2^2$, where $\mathbf{z}, \mathbf{z}'$ are one-hot encoded versions. This means CASMOPOLITAN's kernel is exactly the RBF kernel after one-hot encoding.
Step 2: Hamming graphs have analytic eigendecompositions
Because the Hamming graph is a Cartesian product of complete graphs, its Laplacian eigenvalues can be computed analytically (no numerical methods needed). This is shown by Kondor & Lafferty (2002).
Step 3: Plug in the eigenvalues and simplify
Insert the analytic eigenvalues into the heat kernel formula. After algebraic manipulation, you get CASMOPOLITAN's formula. The paper shows the derivation in Appendix B.
Conclusion: COMBO's graph-based formula and CASMOPOLITAN's Hamming-based formula compute the same kernel values (up to a constant). They're the same kernel wearing different mathematical clothes.
📊 Interactive: Kernel Value Comparison
This plot shows kernel values $k(\mathbf{x}_0, \mathbf{x})$ as a function of Hamming distance. Move your mouse over the plot to see exact values. Notice how Heat, CASMOPOLITAN, and RBF overlap perfectly!
✨ Try this: Uncheck all boxes, then check them one by one. You'll see Heat, CASMOPOLITAN, and RBF produce identical curves—they're the same kernel! Matérn differs slightly because it's a different function.
🧐 Critical Analysis: Strengths, Weaknesses & Open Questions
✅ What This Paper Does Well
- Rigorous unification: The paper doesn't just claim that kernels are "similar"—it proves mathematical equivalence. Theorem 1 (CASMOPOLITAN = COMBO = Heat Kernel) is airtight, with detailed proofs in the appendix. This is theory at its best: taking messy empirical observations and finding the elegant structure beneath.
- Practical speedup: The 2× speedup for COMBO's kernel isn't just academic. For practitioners running hundreds of BO iterations, this halves wall-clock time. The paper shows timing experiments in Appendix C, demonstrating real-world impact.
- Robustness analysis: The experiments on "relocated optima" (Section 4.2) are brilliant. By randomly permuting categories, the paper exposes that BODi and BOSS have hidden biases—they work well when optima happen to align with their assumptions, but fail when optima are arbitrary. Heat kernels, by contrast, are permutation-invariant and don't suffer this flaw.
- Comprehensive benchmarking: The paper tests on 9 different problems (Pest Control, LABS, MaxSAT, biology tasks, etc.) with 20-60 random seeds each. This is far more thorough than typical BO papers, which often test on 3-5 problems with 10 seeds.
- Recipe for new kernels: By establishing the Hamming ↔ Φ-kernel equivalence, the paper provides a systematic way to generate new combinatorial kernels. Want to try a rational quadratic kernel? Just plug it into the Hamming framework. Want a graph Matérn? Use the Φ-kernel framework. This is generative theory.
👥 Reviewer Consensus (Score: 5.25/10)
All four reviewers gave scores of 5-6 (weak accept), recognizing the paper's theoretical contributions but noting presentation issues. Here are key quotes:
"The paper presents a unifying review of methods in combinatorial BO... [showing] that the kernels of popular CASMOPOLITAN and COMBO methods are mathematically equivalent... has profound implications."
— Reviewer 2 (Score: 6)
"All claims are supported with theoretical analysis. Experiments demonstrate the equivalence of certain kernels, and show that a simple heat kernel pipeline can have equivalent performance to state-of-the-art baselines."
— Reviewer 1 (Score: 5)
"[The paper] shows that these Matern-class kernels are heat-kernels... Furthermore, they show that any Hamming kernel is a Φ-kernel, which is a generalization of the Heat kernel."
— Reviewer 4 (Score: 5)
⚠️ Legitimate Concerns
- Limited to categorical variables: The theory assumes each dimension is a finite set with no ordering (categorical). But many real-world problems have ordinal variables (e.g., small/medium/large). The authors argue in Appendix A that "truly ordinal" variables are rare in BO benchmarks, but this feels like a dodge. The theory doesn't extend to mixed categorical-ordinal spaces, which limits applicability.
- Equal-size assumption for equivalence: Theorem 2 (Hamming = Φ-kernels) only holds when all categories have the same number of choices (e.g., all dimensions have 4 options). This is true for many benchmarks, but it's still a constraint. The paper provides a counterexample in Appendix D showing the theorem fails without this assumption.
- No performance improvement over baselines: The paper shows heat kernels match state-of-the-art, but don't beat it. For a practitioner, the takeaway is "you can simplify your pipeline" rather than "this will make your BO better." That's useful, but not groundbreaking.
- BODi's sensitivity unexplained: The paper shows BODi fails on relocated problems (Figure 1) and attributes it to "higher probability of sampling the last category." But this feels like a post-hoc explanation. Why does the HED embedding have this bias? A deeper analysis would strengthen the critique.
- Extensions feel tacked on: Sections on group invariances and additive structures (Section 3.4) are relegated to appendices and lack the rigor of the main theorems. These extensions could be papers on their own, but here they feel like "oh, and this also connects to..."
🔮 Open Questions
- Can the framework extend to continuous + categorical mixed spaces?
- Do heat kernels have any provable advantage (e.g., faster convergence rates) beyond empirical robustness?
- How does kernel choice interact with acquisition function optimization? The paper fixes the acquisition optimizer, but maybe different kernels work better with different optimizers.
- Can we design new kernels that beat heat kernels by exploiting problem structure, while still avoiding the biases of BODi/BOSS?
🔎 The Elephant in the Room
Q: If CASMOPOLITAN and COMBO have been empirically "different" in prior benchmarks, how can they be mathematically identical?
A: The paper reveals that prior benchmarks were comparing full pipelines (kernel + acquisition optimizer + trust region + hyperparameter priors), not just kernels. CASMOPOLITAN used one acquisition optimizer, COMBO used another. Once you isolate the kernel (as this paper does in Figure 1), the equivalence becomes empirically visible. This is a cautionary tale about confounders in empirical ML research.
🎯 Bottom Line
This is a solid theory paper that clarifies the landscape of combinatorial kernels. It won't revolutionize Bayesian optimization, but it will save practitioners time (via faster implementations) and guide future research (via the unifying framework). The main limitation—restriction to categorical variables—prevents this from being a 7+ paper. But for the niche of categorical BO, this is the definitive reference going forward. Verdict: Accept as a poster. It's a valuable contribution that cleans up a messy literature, even if it doesn't open radical new directions.
📊 Experimental Evidence
Figure 1: Empirical Kernel Equivalence
When the pipeline is fixed and only the kernel varies, all heat/Hamming kernels achieve nearly identical performance. This empirically validates the theoretical equivalence.
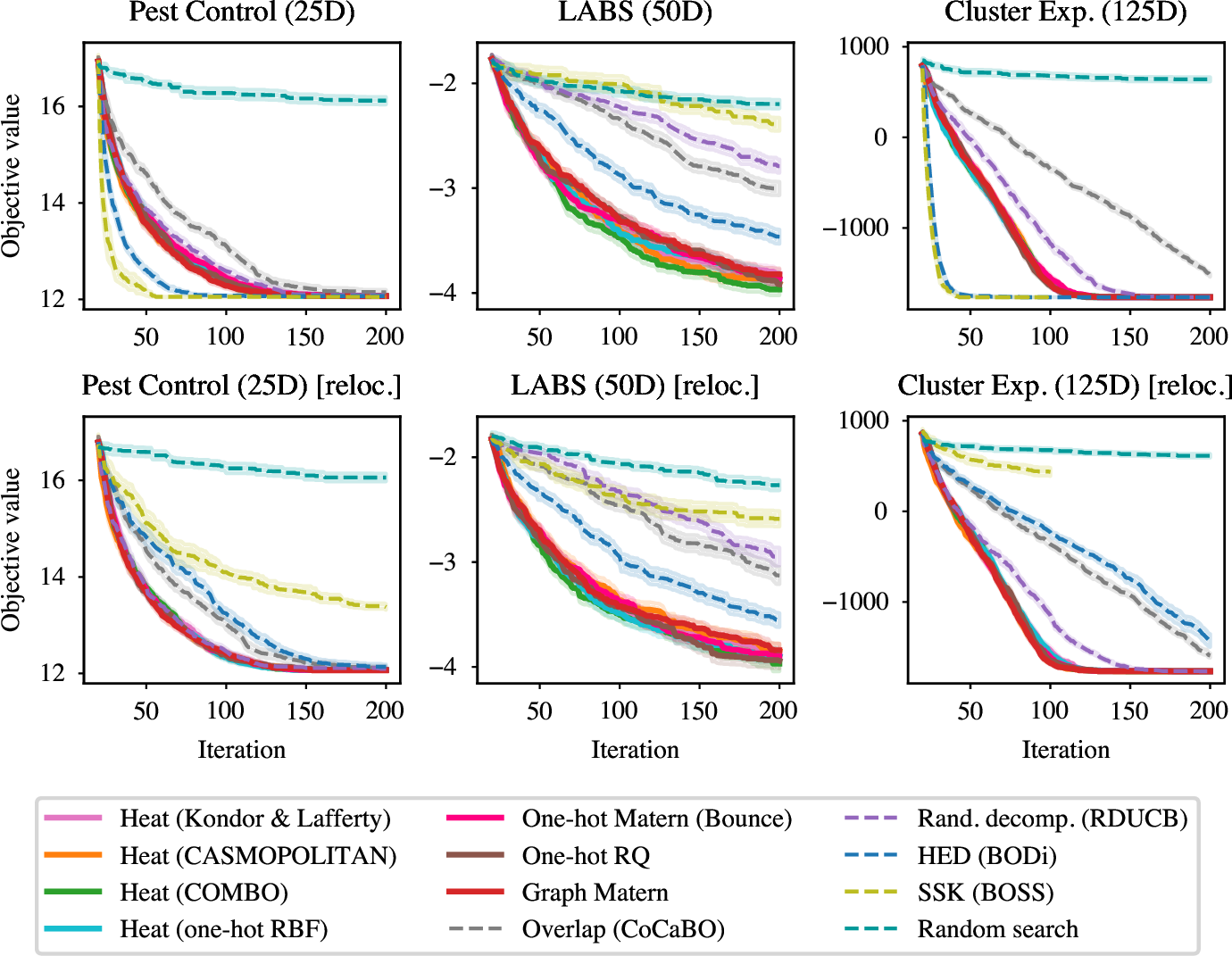
Source: Figure 1 from the paper. Solid lines show heat kernels (overlapping perfectly), while BODi and BOSS show sensitivity to problem structure.
Figure 2: Simple Pipeline Matches State-of-the-Art
A simple heat kernel pipeline (RBF + genetic algorithm + trust region) matches or outperforms complex baselines like Bounce, COMBO, and CASMOPOLITAN.
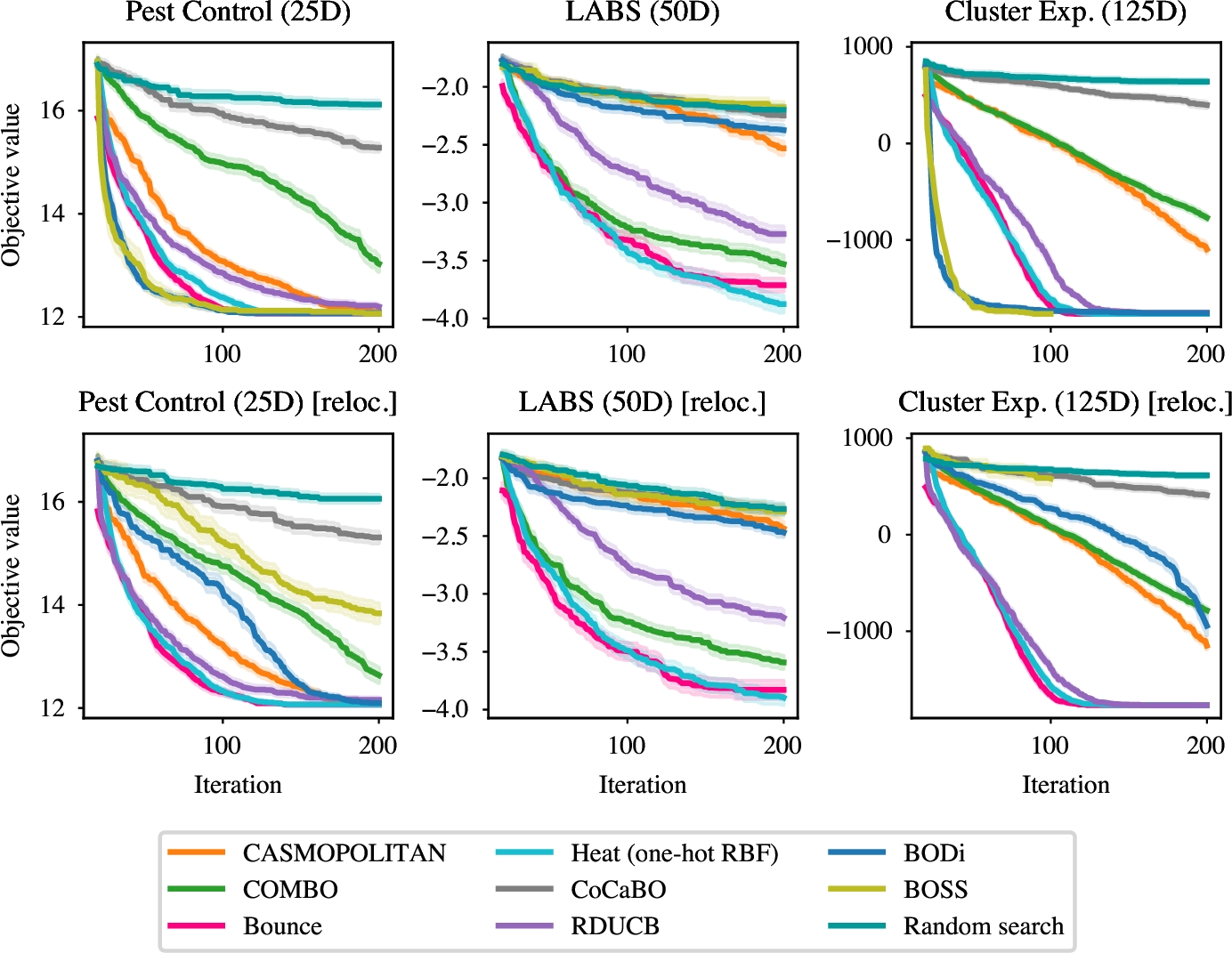
Source: Figure 2 from the paper. The heat kernel pipeline achieves state-of-the-art results with lower complexity.
Figure 3: Wall-Clock Time Comparison
The simplified heat kernel implementation is 2× faster than COMBO's original implementation, while achieving identical performance.
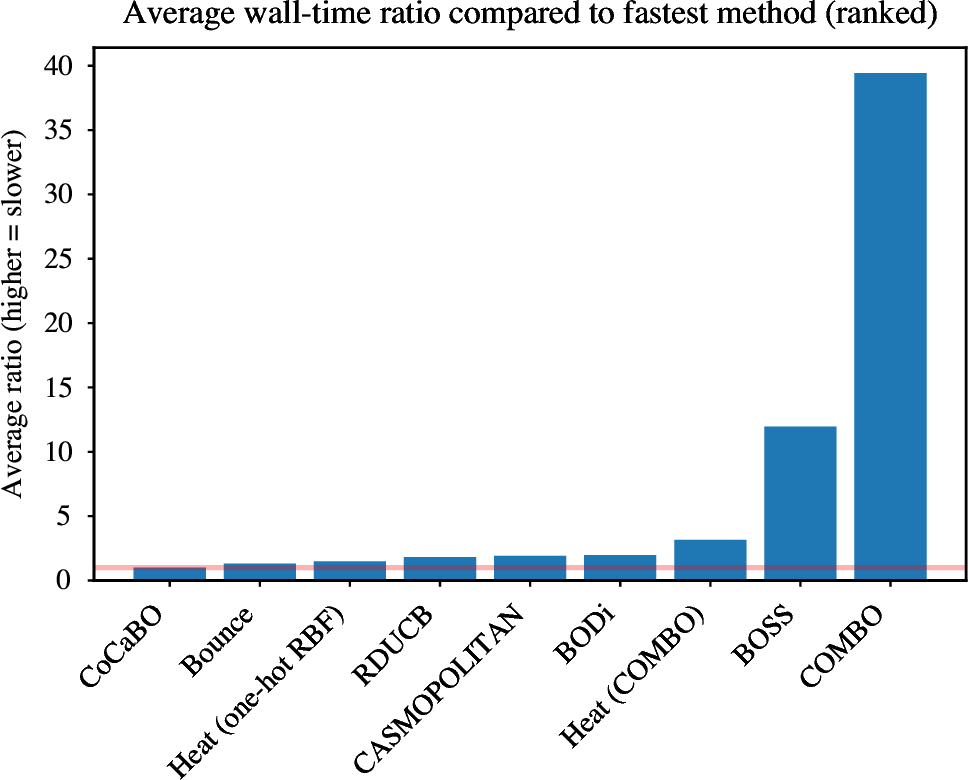
Source: Appendix C from the paper. Heat kernel pipeline is among the fastest methods.
4 Why Should You Care?
🧪 For Practitioners
- ✓ Use the simple RBF-after-one-hot-encoding pipeline. It's fast, robust, and matches complex methods.
- ✓ Avoid BODi and BOSS unless you know your problem has special structure (e.g., string substrings matter).
- ✓ If using COMBO, switch to the authors' faster implementation (2× speedup).
- ✓ Don't waste time benchmarking CASMOPOLITAN vs COMBO—they're the same kernel!
🔬 For Researchers
- ✓ Stop inventing "new" kernels that are just heat kernels with different names.
- ✓ Use the Hamming ↔ Φ-kernel equivalence to systematically explore kernel design.
- ✓ Focus on extending to ordinal/mixed spaces—that's the open frontier.
- ✓ When benchmarking, isolate components (kernel vs optimizer vs trust region) to avoid confounders.